
Formas de suministrar información a un modelo
Numerosas empresas están investigando en la actualidad el potencial de la IA generativa con el objetivo de mejorar su eficacia y adquirir nuevas capacidades. En muchos casos, para desbloquear completamente este potencial, la IA debe acceder a los datos empresariales pertinentes. Si bien los modelos de lenguaje de gran tamaño (LLM) se entrenan con datos de acceso público (como artículos de Wikipedia, libros, índices web, entre otros), lo cual es suficiente para muchas aplicaciones de uso general, hay otras que dependen en gran medida de datos privados, especialmente en el ámbito empresarial.
Existen tres formas principales de suministrar nuevos datos a un modelo:
- Entrenar un modelo desde cero. Esto rara vez resulta viable para la mayoría de las empresas debido a su alto costo, necesidad de abundantes recursos y requisitos de experticia técnica.
- Ajustar un LLM de uso general preexistente. Esto puede reducir los requerimientos de recursos en comparación con el entrenamiento desde cero, pero todavía implica importantes recursos y experiencia. El ajuste fino genera modelos especializados que ofrecen un mejor rendimiento en un dominio específico para el cual se ajustan, pero podrían presentar un rendimiento inferior en otros ámbitos.
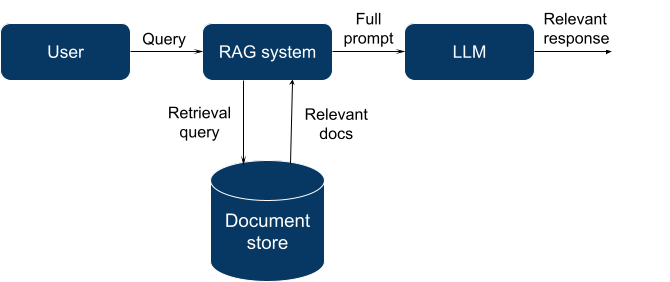
- Recuperación Generación Aumentada (RAG). La premisa es obtener datos relevantes para una consulta e integrarlos en el contexto del LLM para que pueda "basar" sus propios resultados en dicha información. En este contexto, esos datos pertinentes son conocidos como "datos de conexión a tierra". Si bien RAG complementa los modelos LLM genéricos, la información que se puede proporcionar se ve limitada por el tamaño de la ventana de contexto del LLM (es decir, la cantidad de texto que el LLM puede procesar en una sola instancia al generar información).
En la actualidad, RAG constituye la forma más accesible de suministrar nueva información a un LLM, por lo que nos centraremos en este método y exploraremos detalladamente al respecto.
Recuperación Generación Aumentada
A grandes rasgos, RAG implica emplear un motor de búsqueda o recuperación para obtener un conjunto pertinente de documentos para una consulta específica.
Para ello, se pueden emplear diversos sistemas existentes: un motor de búsqueda de texto completo (como Elasticsearch junto con técnicas tradicionales de recuperación de información), una base de datos de uso general con una extensión de búsqueda vectorial (Postgres con pgvector, Elasticsearch con el plugin de búsqueda vectorial) o una base de datos especializada diseñada específicamente para la búsqueda de vectores.
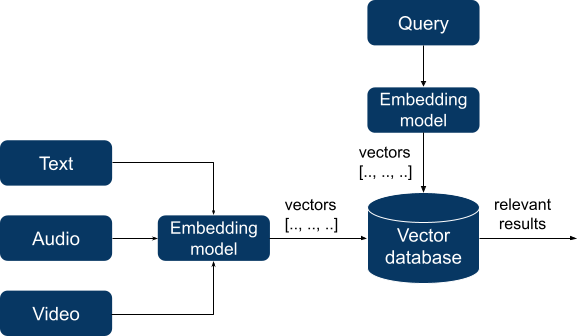
En los dos últimos casos, RAG se asemeja a la búsqueda semántica. Durante mucho tiempo, la búsqueda semántica fue un dominio altamente especializado y complejo que implicaba el uso de lenguajes de consulta exóticos y bases de datos especializadas. La indexación de datos requería una preparación meticulosa y la elaboración de grafos de conocimiento, pero los avances recientes en el aprendizaje profundo han transformado de forma radical este panorama. Las aplicaciones contemporáneas de búsqueda semántica se basan en la incorporación de modelos que logran aprender exitosamente patrones semánticos en los datos presentados. Estos modelos toman datos no estructurados (texto, audio o incluso video) como entrada y los convierten en vectores numéricos de longitud fija, convirtiendo así los datos no estructurados en una forma numérica que posiblemente pueda utilizarse en cálculos. De esta manera, se vuelve viable calcular la distancia entre vectores empleando una métrica de distancia específica, y la distancia resultante reflejará la similitud semántica entre los vectores y, por ende, entre los datos originales.
Estos vectores son indexados por una base de datos de vectores, y al realizar la consulta, nuestra consulta también se convierte en un vector. La base de datos busca los N vectores más cercanos (según una métrica de distancia seleccionada, como la similitud del coseno) a un vector de consulta y los devuelve.
Una base de datos de vectores se encarga de tres aspectos fundamentales:
- Indexación. La base de datos crea un índice de vectores mediante algún algoritmo integrado (ejemplo: hash sensible a la localidad (LSH) o mundo pequeño navegable jerárquico (HNSW)) para precalcular datos y acelerar las consultas.
- Consulta. La base de datos emplea un vector de consulta y un índice para encontrar los vectores más relevantes en una base de datos.
- Postprocesamiento. Una vez obtenido el conjunto de resultados, en ocasiones es posible que deseemos realizar un paso adicional, como el filtrado de metadatos o la reasignación de categorías dentro del conjunto de resultados para mejorar el desempeño.
El objetivo de una base de datos de vectores es ofrecer una manera rápida, fiable y eficaz de almacenar y consultar datos. La velocidad de recuperación y la calidad de la búsqueda pueden verse afectadas por la selección del tipo de índice. Además de los ya mencionados LSH y HNSW, existen otros tipos de índices, cada uno con sus propias ventajas y limitaciones. En la mayoría de las bases de datos, la elección del tipo de índice se realiza automáticamente, pero en algunas, es posible seleccionar manualmente un tipo de índice para controlar el equilibrio entre la velocidad y la precisión.
En DataRobot, consideramos que esta técnica ha venido para quedarse. El ajuste puede implicar una preparación de datos sumamente sofisticada para transformar el texto sin formato en datos aptos para el entrenamiento, y más que ciencia, es un arte convencer a los LLM de "aprender" nueva información mediante el ajuste, manteniendo al mismo tiempo su conocimiento general y siguiendo los patrones de comportamiento.
Los LLM suelen ser altamente efectivos para aplicar el conocimiento proporcionado en contexto, especialmente cuando se suministra la información más relevante, por lo que contar con un buen sistema de recuperación resulta crucial.
Es fundamental tener en cuenta que la elección del modelo de integración utilizado para RAG es crucial. Aunque no forma parte de la base de datos, seleccionar el modelo de integración adecuado para su aplicación resulta fundamental para lograr un buen rendimiento. Además, si bien se lanzan constantemente modelos nuevos y mejorados, el cambio a un nuevo modelo requiere reindexar por completo toda la base de datos.
Evaluación de sus alternativas
La elección de una base de datos en un entornoLa gestión empresarial no es una tarea sencilla. Una base de datos suele ser el núcleo de la infraestructura de software que administra un activo empresarial fundamental: los datos.
Por lo general, al elegir una base de datos, buscamos:
- Almacenamiento fiable
- Consulta eficiente
- Capacidad para realizar inserciones, actualizaciones y eliminaciones de datos de forma detallada (CRUD)
- Configurar múltiples usuarios con diversos niveles de acceso (RBAC)
- Coherencia de los datos (comportamiento predecible al modificar datos)
- Capacidad de recuperación frente a fallos
- Escalabilidad de acuerdo al tamaño de nuestros datos
Esta enumeración no pretende ser exhaustiva y puede parecer obvia, pero no todas las nuevas bases de datos vectoriales cumplen con estas características. A menudo, la disponibilidad de funciones empresariales es la que determina la elección final entre una base de datos madura y conocida que ofrece búsqueda de vectores a través de extensiones, y una base de datos más reciente exclusivamente de vectores.
Las bases de datos exclusivas de vectores cuentan con soporte nativo para la búsqueda de vectores y pueden ejecutar consultas con gran rapidez, pero a menudo carecen de funcionalidades empresariales y son relativamente nuevas en el mercado. Desarrollar funciones complejas y probarlas lleva tiempo, por lo que no es sorprendente que los primeros usuarios puedan experimentar interrupciones y pérdida de datos. Por otro lado, en bases de datos existentes que proporcionan búsqueda de vectores a través de extensiones, un vector no es tratado como un elemento central y el rendimiento de la consulta puede ser considerablemente menor.
Clasificaremos todas las bases de datos actuales que ofrecen búsqueda de vectores en los siguientes grupos y luego las analizaremos con más detalle:
- Bibliotecas de búsqueda de vectores
- Bases de datos exclusivas de vectores
- Bases de datos NoSQL con búsqueda vectorial
- Bases de datos SQL con búsqueda vectorial
- Soluciones de búsqueda de vectores de proveedores en la nube
Bibliotecas de búsqueda de vectores
Las bibliotecas de búsqueda de vectores como FAISS y ANNOY no son bases de datos en sí, sino que proporcionan índices de vectores en memoria y ofrecen opciones limitadas de persistencia de datos. Aunque estas características no son ideales para usuarios que necesitan una base de datos empresarial completa, estas bibliotecas destacan por su rápida búsqueda de vecinos más cercanos y por ser de código abierto. Son eficientes en el manejo de datos de alta dimensión y altamente configurables (permiten seleccionar el tipo de índice y otros parámetros).
En general, son útiles para crear prototipos e integrar en aplicaciones simples, pero no son idóneas para el almacenamiento a largo plazo de datos multiusuario.
Bases de datos exclusivas de vectores
Este grupo incluye varios productos como Milvus, Chroma, Pinecone, Weaviate, entre otros. Aunque presentan diferencias significativas entre ellos, todos están diseñados específicamente para almacenar y recuperar vectores. Están optimizados para búsquedas eficientes de similitudes con indexación, y admiten datos de alta dimensión y operaciones vectoriales de forma nativa.
La mayoría de estas bases de datos son relativamente nuevas y es posible que no cuenten con todas las características empresariales mencionadas anteriormente, como la capacidad CRUD, recuperación probada de fallos, RBAC, entre otros. En su mayoría, pueden almacenar datos en bruto, el vector de incrustación y una pequeña cantidad de metadatos, pero no admiten otros tipos de índices o datos relacionales, lo que significa que es necesario utilizar otra base de datos secundaria y asegurar la coherencia entre ellas.
Suelen destacarse por su rendimiento excepcional y son una excelente opción cuando se manejan datos multimodales (imágenes, audio o vídeo).
Bases de datos NoSQL con búsqueda vectorial
Varias bases de datos NoSQL han añadido recientemente capacidades de búsqueda vectorial a sus productos, como MongoDB, Redis, neo4j, y ElasticSearch. Estas bases de datos ofrecen buenas características empresariales, han alcanzado un nivel de madurez y cuentan con una comunidad sólida, pero proporcionan funcionalidades de búsqueda vectorial a través de extensiones que pueden resultar en un rendimiento inferior al ideal y una falta de soporte de primera clase para la búsqueda de vectores. Destaca Elasticsearch, diseñado originalmente para búsquedas de texto completo, que ya cuenta con numerosas funciones tradicionales de recuperación de información que pueden emplearse junto con la búsqueda de vectores.
Las bases de datos NoSQL con búsqueda vectorial son una buena elección cuando ya se ha invertido en ellas y se necesita la búsqueda vectorial como una característica adicional, aunque no sea de alta demanda.
Bases de datos SQL con búsqueda vectorial
Este grupo es similar al anterior, pero aquí se incluyen actores como PostgreSQL y ClickHouse. Ofrecen una amplia gama de características empresariales, están bien documentados y cuentan con comunidades sólidas. Como desventajas, están diseñados para datos estructurados y escalarlos requiere de experiencia específica.
Su caso de uso también es similar: una elección acertada cuando ya se dispone de ellos y se cuenta con la experiencia para ejecutarlos correctamente.
Soluciones de búsqueda de vectores de proveedores en la nube
Los proveedores de hiperescala también ofrecen servicios de búsqueda de vectores. Generalmente, estos servicios cuentan con funciones básicas para la búsqueda de vectores (permitiendo seleccionar un modelo de incrustación, tipo de índice y otros parámetros), buena interoperabilidad con el resto de la plataforma en la nube y una mayor flexibilidad en cuanto a costos, especialmente si se utilizan otros servicios dentro de la plataforma. No obstante, presentan diferentes niveles de madurez y conjuntos de características: la búsqueda de vectores de Google Cloud utiliza un rápido algoritmo de búsqueda de índice patentado llamado ScaNN y filtrado de metadatos, aunque no es muy fácil de usar; mientras que la búsqueda de vectores de Azure ofrece capacidades de búsqueda estructurada, pero aún se encuentra en fase de vista previa, entre otros.
Estas entidades de búsqueda de vectores pueden ser gestionadas mediante funcionalidades empresariales de la plataforma, como IAM (Identity and Access Management), pero no son tan intuitivas ni ideales para un uso general en la nube.
Tomando la decisión correcta
El principal caso de uso de las bases de datos vectoriales en este contexto es proporcionar información relevante a un modelo. Para su próximo proyecto de LLM, puede optar por una base de datos de entre la variedad existente que ofrezca capacidades de búsqueda de vectores a través de extensiones, o por nuevas bases de datos exclusivamente de vectores que brindan soporte nativo para vectores y consultas rápidas.
La elección dependerá de si se necesitan funcionalidades empresariales o un rendimiento a gran escala, así como de la arquitectura de implementación y el nivel de madurez deseado (investigación, prototipado o producción). También se debe considerar qué bases de datos ya están presentes en la infraestructura y si se manejan datos multimodales. En cualquier caso, sea cual sea la elección, es recomendable tomar medidas de precaución: tratar una nueva base de datos como una caché de almacenamiento secundaria en lugar de un punto central de operaciones, y abstraer las operaciones de base de datos en código para facilitar la adaptación a las siguientes iteraciones del entorno vectorial.RAG.
Formas en que DataRobot puede ser beneficioso
En la actualidad, existe una amplia variedad de bases de datos vectoriales entre las que elegir. Cada una tiene sus ventajas y desventajas: ninguna base de datos vectorial será ideal para todos los casos de uso de IA generativa de su organización. Por lo tanto, es crucial mantener la capacidad de elección y optar por una solución que le permita personalizar sus soluciones de IA generativa para casos de uso específicos, adaptándose a medida que evolucionan sus necesidades o el mercado.
La plataforma DataRobot AI le brinda la posibilidad de utilizar su propia base de datos vectorial, la cual sea adecuada para la solución que esté desarrollando. Si en el futuro necesita realizar cambios, podrá modificar su base de datos vectorial sin afectar su entorno de producción ni sus flujos de trabajo.
Acerca del Autor
Nick Volynets
Nick Volynets es un ingeniero de datos senior que trabaja en la oficina del CTO, donde disfruta estar en el centro de la innovación de DataRobot. Se interesa por el aprendizaje automático a gran escala y siente pasión por la IA y su impacto.