

Imagen por autor
La utilización de Pipelines de Scikit-learn puede simplificar los pasos de preprocesamiento y modelado, reducir la complejidad del código, garantizar la coherencia en el preprocesamiento de datos, ayudar con la optimización de hiperparámetros y hacer que tu flujo de trabajo sea más organizado y fácil de mantener. Al combinar múltiples transformaciones y el modelo final en una entidad única, los Pipelines mejoran la reproducibilidad y hacen que todo sea más eficiente.
En este tutorial, trabajaremos con el conjunto de datos de Rotación bancaria de Kaggle para entrenar un clasificador de bosque aleatorio. Compararemos el enfoque convencional de preprocesamiento de datos y entrenamiento de modelos con un método más eficiente que utiliza Pipelines de Scikit-learn y ColumnTransformers.
En el proceso de procesamiento de datos, aprenderemos a transformar columnas categóricas y numéricas de forma individual. Comenzaremos con un estilo de código tradicional y luego mostraremos una manera mejor de realizar un procesamiento similar.
Después de extraer los datos del archivo zip, carga el archivo `train.csv` con “id” como columna de índice. Elimina columnas innecesarias y baraja el conjunto de datos.
import pandas as pd
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(('CustomerId', 'Surname'), axis=1)
bank_df = bank_df.sample(frac=1)
bank_df.head()Tenemos columnas categóricas, enteras y flotantes. El conjunto de datos parece bastante limpio.

Código sencillo de aprendizaje de Scikit
Como científico de datos, he escrito este código en varias ocasiones. Nuestro objetivo es completar los valores faltantes para características tanto categóricas como numéricas. Para lograrlo, utilizaremos un `SimpleImputer` con diferentes estrategias para cada tipo de característica.
Una vez completados los valores faltantes, convertiremos las características categóricas en números enteros y aplicaremos una escala mínima-máxima a las características numéricas.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
cat_col = (1,2)
num_col = (0,3,4,5,6,7,8,9)
# Rellenar valores categóricos faltantes
cat_impute = SimpleImputer(strategy="most_frequent")
bank_df.iloc[:,cat_col] = cat_impute.fit_transform(bank_df.iloc[:,cat_col])
# Rellenar valores numéricos faltantes
num_impute = SimpleImputer(strategy="median")
bank_df.iloc[:,num_col] = num_impute.fit_transform(bank_df.iloc[:,num_col])
# Codificar características categóricas como un array de enteros
cat_encode = OrdinalEncoder()
bank_df.iloc[:,cat_col] = cat_encode.fit_transform(bank_df.iloc[:,cat_col])
# Escalar valores numéricos
scaler = MinMaxScaler()
bank_df.iloc[:,num_col] = scaler.fit_transform(bank_df.iloc[:,num_col])
bank_df.head()Como resultado, obtenemos un conjunto de datos limpio y transformado con solo valores enteros o de punto flotante.
Código de Pipelines de Scikit-learn
Vamos a transformar el código anterior utilizando `Pipeline` y `ColumnTransformer`. En lugar de aplicar la técnica de preprocesamiento, crearemos dos pipelines. Uno será para columnas numéricas y el otro para columnas categóricas.
- En el proceso numérico, utilizaremos una imputación simple con una estrategia de "media" y aplicaremos un escalado mínimo-máximo para la normalización.
- En el pipeline categórico, usaremos el imputador simple con la estrategia "más_frecuente" y el codificador ordinal para convertir las categorías en valores numéricos.
Combinaremos ambos pipelines utilizando ColumnTransformer y proporcionaremos los índices de columnas correspondientes a cada uno. Esto ayudará a aplicar estos pipelines en columnas específicas. Por ejemplo, el pipeline de transformación categórica se aplicará solo a las columnas 1 y 2.
Nota: "remainder = 'passthrough'" significa que las columnas que no han sido procesadas se agregarán al final. En nuestro caso, es la columna de destino.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Identificar columnas numéricas y categóricas
cat_col = (1,2)
num_col = (0,3,4,5,6,7,8,9)
# Transformadores para datos numéricos
transformador_numerico = Pipeline(steps=(
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
))
# Transformadores para datos categóricos
transformador_categorico = Pipeline(steps=(
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
))
# Combinar transformadores en un ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=(
('num', transformador_numerico, num_col),
('cat', transformador_categorico, cat_col)
),
remainder="passthrough"
)
# Aplicar el pipeline de preprocesamiento
bank_df = preproc_pipe.fit_transform(bank_df)
bank_df(0)Después de la transformación, la matriz resultante contiene un valor de transformación numérica al principio y un valor de transformación categórica al final, según el orden de los pipelines en el transformador de columnas.
array((0.712 , 0.24324324, 0.6 , 0. , 0.33333333,
1. , 1. , 0.76443485, 2. , 0. ,
0. ))Para visualizar la canalización, puede ejecutar el objeto de canalización en Jupyter Notebook. Asegúrese de tener la última versión de Scikit-learn.

Para entrenar y evaluar nuestro modelo, es necesario dividir nuestro conjunto de datos en dos subconjuntos: entrenamiento y prueba.
Para lograr esto, primero creamos variables dependientes e independientes y las convertimos en matrices NumPy. Luego, utilizamos la función `train_test_split` para dividir el conjunto de datos en dos subconjuntos.
from sklearn.model_selection import train_test_split
X = bank_df.drop("Exited", axis=1).values
y = bank_df.Exited.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)Código sencillo de aprendizaje con Scikit
La forma convencional de escribir código de entrenamiento implica realizar primero la selección de características utilizando "SelectKBest" y luego proporcionar la nueva característica a nuestro modelo de Clasificador de bosque aleatorio.
Primero entrenamos el modelo utilizando el conjunto de entrenamiento y evaluamos los resultados utilizando el conjunto de datos de prueba.
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
KBest = SelectKBest(chi2, k="all")
X_train = KBest.fit_transform(X_train, y_train)
X_test = KBest.transform(X_test)
model = RandomForestClassifier(n_estimators=100, random_state=125)
model.fit(X_train,y_train)
model.score(X_test, y_test)Obtuvimos una puntuación de precisión bastante alta.
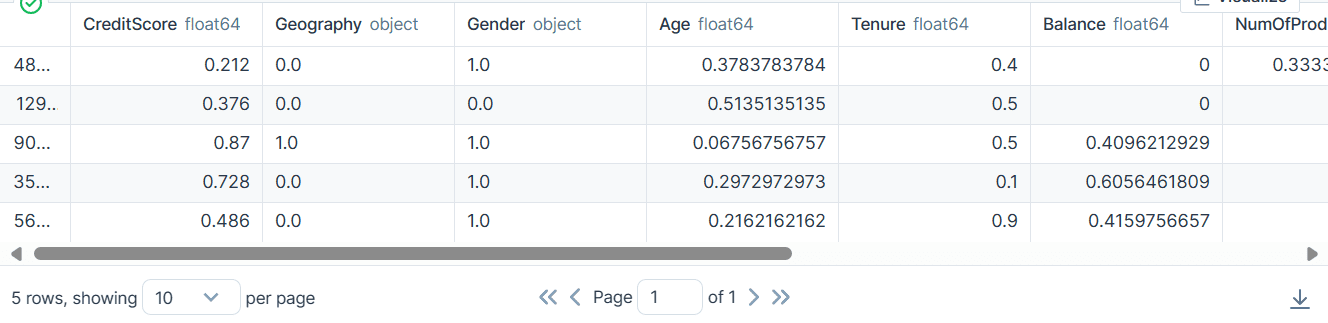
Código de canalizaciones de Scikit-learn
Usamos la función `Pipeline` para combinar ambos pasos de entrenamiento en una canalización. Luego podemos ajustar el modelo al conjunto de entrenamiento y evaluarlo en el conjunto de prueba.
KBest = SelectKBest(chi2, k="all")
model = RandomForestClassifier(n_estimators=100, random_state=125)
train_pipe = Pipeline(
steps=(
("KBest", KBest),
("RFmodel", model),
)
)
train_pipe.fit(X_train,y_train)
train_pipe.score(X_test, y_test)Obtuvimos resultados similares, pero el código parece ser más eficiente y sencillo. Es bastante fácil agregar o eliminar nuevos pasos del proceso de entrenamiento.
Ejecute el objeto de canalización para visualizar la canalización.
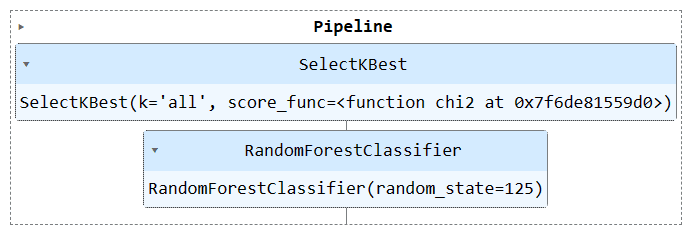
Ahora combinaremos el proceso de preprocesamiento y el de entrenamiento creando otra canal y añadiendo ambos canales.
A continuación se muestra el código completo:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
#loading the data
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(('CustomerId', 'Surname'), axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(("Exited"),axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = (1,2)
num_col = (0,3,4,5,6,7,8,9)
# Transformers for numerical data
numerical_transformer = Pipeline(steps=(
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
))
# Transformers for categorical data
categorical_transformer = Pipeline(steps=(
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
))
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=(
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
),
remainder="passthrough"
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=(
("KBest", KBest),
("RFmodel", model),
)
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=(
("preprocessor", preproc_pipe),
("train", train_pipe),
)
)
# running the complete pipeline
complete_pipe.fit(X_train,y_train)
# model accuracy
complete_pipe.score(X_test, y_test)Producción:
Visualizando la canalización completa.

Una de las principales ventajas de utilizar canalizaciones es que puede almacenar la canalización con el modelo. Durante la inferencia, solo necesita cargar el objeto de canalización, que estará listo para procesar los datos sin procesar y brindar predicciones precisas. No será necesario volver a escribir las funciones de procesamiento y transformación en el archivo de la aplicación, ya que funcionará.
El proceso de aprendizaje automático se vuelve más eficaz y ahorra tiempo al utilizar tuberías. Para comenzar, se guarda la tubería utilizando la biblioteca skops-dev/skops.
import skops.io as sio
sio.dump(complete_pipe, "bank_pipeline.skops")A continuación, se carga la tubería guardada y se muestra.
new_pipe = sio.load("bank_pipeline.skops", trusted=True)
new_pipeLa carga de la tubería se realizó correctamente.
Para evaluar la tubería cargada, se realizarán predicciones en el conjunto de prueba y se calcularán la precisión y las puntuaciones F1.
from sklearn.metrics import accuracy_score, f1_score
predictions = new_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))Se observa la necesidad de focalizarse en las clases minoritarias para mejorar la puntuación en F1.
Los archivos y el código del proyecto están disponibles en Espacio de trabajo de Deepnote. El espacio de trabajo contiene dos cuadernos: uno con la tubería Scikit-learn y otro sin ella.
En este tutorial, se ha aprendido cómo las tuberías de Scikit-learn pueden optimizar los flujos de trabajo de aprendizaje automático al encadenar transformaciones y modelos de datos. Al combinar el preprocesamiento y el entrenamiento de modelos en un único objeto de tubería, se simplifica el código, se garantizan transformaciones de datos coherentes y se hace que los flujos de trabajo sean más organizados y reproducibles.
Abid Ali Awan (@1abidaliawan) es un científico de datos certificado que disfruta creando modelos de aprendizaje automático. Actualmente, se enfoca en crear contenido y blogs técnicos sobre tecnologías de ciencia de datos y aprendizaje automático. Abid posee una Maestría en Gestión de Tecnología y una Licenciatura en Ingeniería de Telecomunicaciones. Su objetivo es desarrollar un producto de inteligencia artificial utilizando una red neuronal gráfica para ayudar a los estudiantes que luchan contra enfermedades mentales.