

Imagen por autor
GitHub Actions es una característica poderosa de la plataforma GitHub que permite automatizar los flujos de trabajo de desarrollo de software, como probar, crear e implementar código. Esto no solo acelera el proceso de desarrollo, sino que también lo hace más confiable y eficiente.
En este tutorial, examinaremos cómo utilizar GitHub Actions para un proyecto de aprendizaje automático (ML) destinado a principiantes. Desde la configuración de nuestro proyecto de ML en GitHub hasta la creación de un flujo de trabajo de GitHub Actions que automatiza las tareas de ML, cubriremos todo lo que necesitas saber.
GitHub Actions es una herramienta potente que ofrece una canalización de integración y entrega continua (CI/CD) para todos los repositorios de GitHub de forma gratuita. Automatiza todo el flujo de trabajo de desarrollo de software, desde la creación y las pruebas hasta la implementación del código, todo dentro de la plataforma GitHub. Puedes utilizarlo para mejorar la eficiencia de tu desarrollo e implementación.
Características clave de las acciones de GitHub
Ahora vamos a aprender sobre los componentes clave del flujo de trabajo.
Flujos de trabajo
Los flujos de trabajo son procesos automatizados que defines en tu repositorio de GitHub. Están compuestos por uno o más trabajos y pueden activarse mediante eventos de GitHub, como una inserción, una solicitud de extracción, la creación de un problema o mediante flujos de trabajo. Los flujos de trabajo se definen en un archivo YML dentro del directorio .github/workflows de tu repositorio. Puedes editarlo y volver a ejecutar el flujo de trabajo directamente desde el repositorio de GitHub.
Trabajos y Pasos
Dentro de un flujo de trabajo, los trabajos definen un conjunto de pasos que se ejecutan en el mismo ejecutor. Cada paso de un trabajo puede ejecutar comandos o acciones, que son fragmentos de código reutilizables que pueden realizar una tarea específica, como formatear el código o entrenar el modelo.
Eventos
Los flujos de trabajo pueden activarse mediante varios eventos de GitHub, como push, pull request, forks, stars, lanzamientos y más. También puedes programar flujos de trabajo para que se ejecuten en momentos específicos utilizando la sintaxis cron.
Corredores
Los corredores son los entornos/máquinas virtuales donde se ejecutan los flujos de trabajo. GitHub proporciona ejecutores alojados en entornos Linux, Windows y macOS, o puedes alojar tu propio ejecutor para tener más control sobre el entorno.
Comportamiento
Las acciones son unidades de código reutilizables que puedes utilizar como pasos dentro de tus trabajos. Puedes crear tus propias acciones o utilizar acciones compartidas por la comunidad GitHub en GitHub Marketplace.
GitHub Actions facilita a los desarrolladores la automatización de sus flujos de trabajo de compilación, prueba e implementación directamente dentro de GitHub, lo que ayuda a mejorar la productividad y agilizar el proceso de desarrollo.
En este proyecto, utilizaremos dos acciones:
- acciones/pago@v3: para revisar tu repositorio para que el flujo de trabajo pueda acceder al archivo y a los datos.
- iterativo/setup-cml@v2: para mostrar las métricas del modelo y la matriz de confusión debajo de la confirmación como un mensaje.
Trabajaremos en un proyecto sencillo de aprendizaje automático utilizando el conjunto de datos de Rotación Bancaria de Kaggle para entrenar y evaluar un clasificador de bosque aleatorio.
Configuración
- Crearemos el repositorio de GitHub proporcionando el nombre y la descripción, verificando el archivo Léame y la licencia.
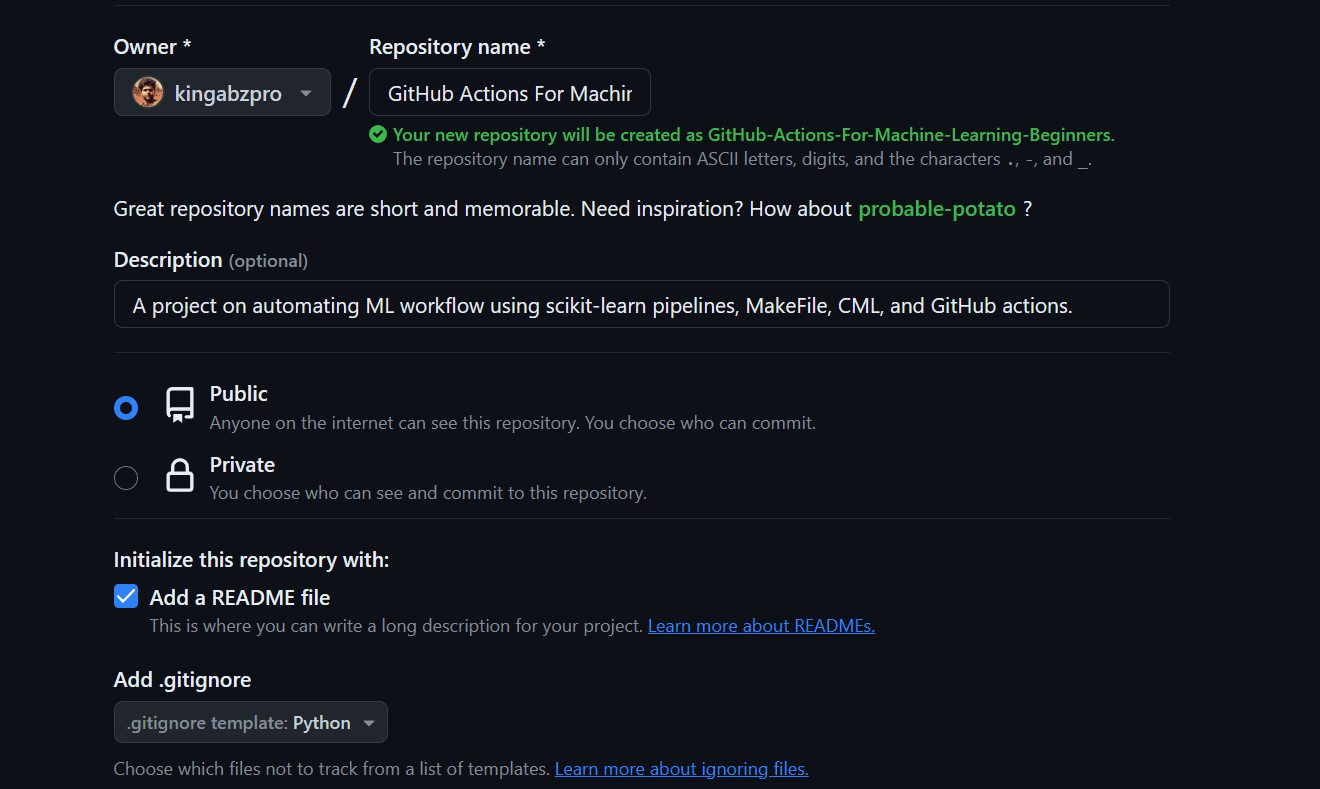
- Ve al director del proyecto y clona el repositorio.
- Cambia el directorio a la carpeta del repositorio.
- Inicia el editor de código. En nuestro caso, es VSCode.
$ git clone https://github.com/kingabzpro/GitHub-Actions-For-Machine-Learning-Beginners.git
$ cd .GitHub-Actions-For-Machine-Learning-Beginners
$ code .
- Crea un archivo `requirements.txt` y añade todos los paquetes necesarios para ejecutar el flujo de trabajo correctamente.
pandas
scikit-learn
numpy
matplotlib
skops
black- Descarga los datos desde Kaggle usando el enlace y extráelos en la carpeta principal.
- El conjunto de datos es grande, así que debemos instalar GitLFS en nuestro repositorio y hacer track del archivo CSV de entrenamiento.
$ git lfs install
$ git lfs track train.csvCódigo de Entrenamiento y Evaluación
En esta sección, escribiremos el código que entrenará, evaluará y guardará las canalizaciones del modelo. El código es de mi tutorial anterior, Optimice su flujo de trabajo de aprendizaje automático con Scikit-learn Pipelines. Si deseas conocer cómo funciona el proceso scikit-learn, deberías leerlo.
- Crea un archivo `train.py` y copia y pega el siguiente código.
- El código utiliza ColumnTransformer y Pipeline para preprocesar los datos y Pipeline para la selección de características y el entrenamiento de modelos.
- Después de evaluar el rendimiento del modelo, tanto las métricas como la matriz de confusión se guardan en la carpeta principal. Estas métricas se utilizarán más adelante por la acción CML.
- Al final, el proceso final de scikit-learn se guarda para la inferencia del modelo.
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler, OrdinalEncoder
from sklearn.metrics import accuracy_score, f1_score
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
import skops.io as sio
# loading the data
bank_df = pd.read_csv("train.csv", index_col="id", nrows=1000)
bank_df = bank_df.drop(("CustomerId", "Surname"), axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into trainingy conjuntos de prueba
X = bank_df.drop(("Exited"), axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = (1, 2)
num_col = (0, 3, 4, 5, 6, 7, 8, 9)
# Transformers for numerical data
numerical_transformer = Pipeline(
steps=(("imputer", SimpleImputer(strategy="mean")), ("scaler", MinMaxScaler()))
)
# Transformers for categorical data
categorical_transformer = Pipeline(
steps=(
("imputer", SimpleImputer(strategy="most_frequent")),
("encoder", OrdinalEncoder()),
)
)
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=(
("num", numerical_transformer, num_col),
("cat", categorical_transformer, cat_col),
),
remainder="passthrough",
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=(
("KBest", KBest),
("RFmodel", model),
)
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=(
("preprocessor", preproc_pipe),
("train", train_pipe),
)
)
# running the complete pipeline
complete_pipe.fit(X_train, y_train)
## Model Evaluation
predictions = complete_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
## Confusion Matrix Plot
predictions = complete_pipe.predict(X_test)
cm = confusion_matrix(y_test, predictions, labels=complete_pipe.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=complete_pipe.classes_)
disp.plot()
plt.savefig("model_results.png", dpi=120)
## Write metrics to file
with open("metrics.txt", "w") as outfile:
outfile.write(f"nAccuracy = {round(accuracy, 2)}, F1 Score = {round(f1, 2)}nn")
# saving the pipeline
sio.dump(complete_pipe, "bank_pipeline.skops")Hemos logrado un resultado satisfactorio.
$ python train.py
Accuracy: 88.0% F1: 0.77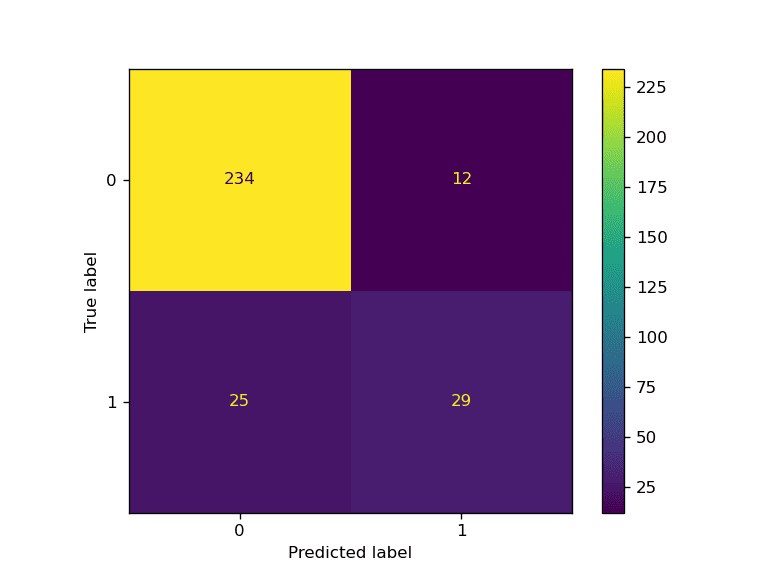
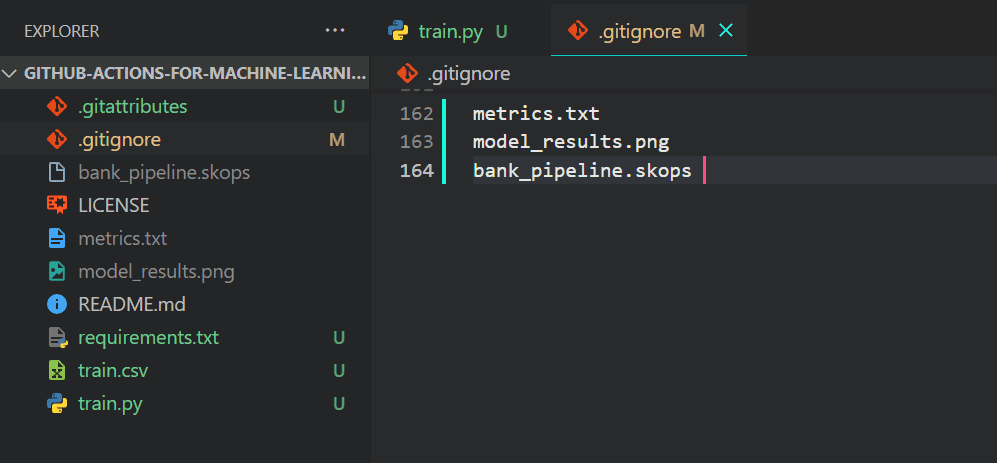
No deseamos que Git envíe archivos de salida, ya que siempre se generan al final del código, por lo que los agregaremos al archivo .gitignore.
Simplemente escriba `.gitignore` en la terminal para iniciar el archivo.
Agregue los siguientes nombres de archivo.
metrics.txt
model_results.png
bank_pipeline.skopsAsí es como debería verse en su VSCode.
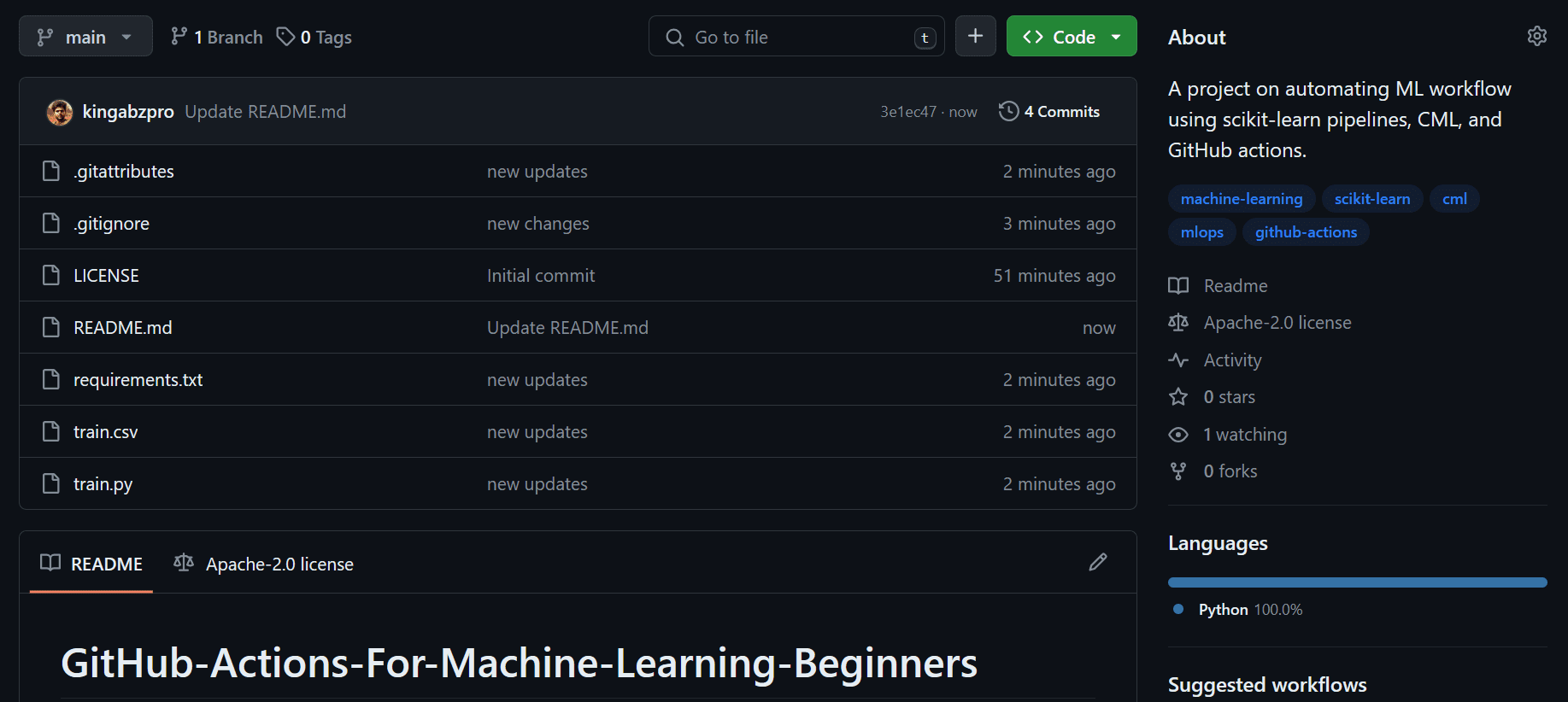
git add .
git commit -m "nuevos cambios"
git push origin mainAsí es como debería lucir tu repositorio de GitHub.
LMC
Antes de comenzar a trabajar en el flujo de trabajo, es importante comprender el propósito del comportamiento del Aprendizaje Automático Continuo (CML). Las funciones de CML se utilizan en el flujo de trabajo para automatizar el proceso de generación de un informe de evaluación del modelo. ¿Qué significa esto? Bueno, cuando enviamos cambios a GitHub, se generará automáticamente un informe bajo la confirmación. Este informe incluirá métricas de rendimiento y una matriz de confusión, y también recibiremos un correo electrónico con toda esta información.
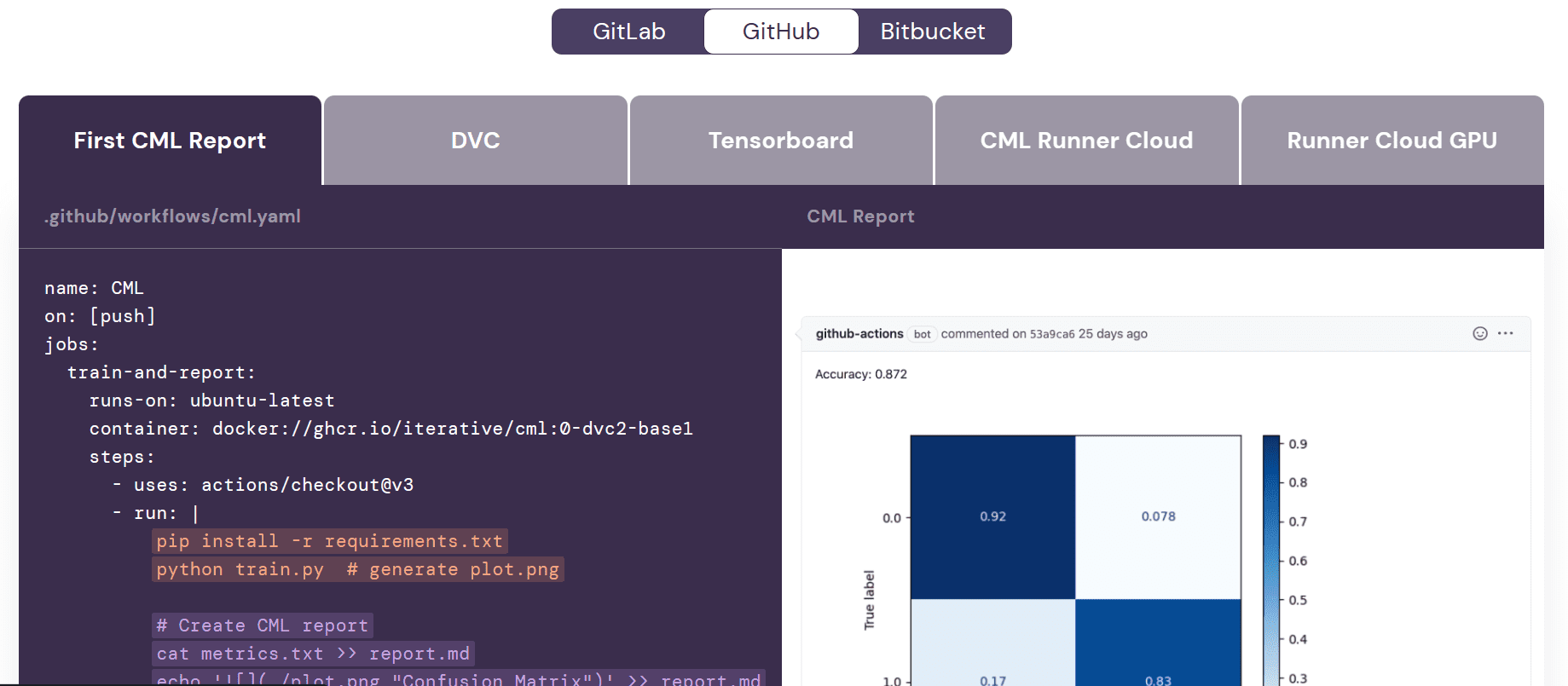
Acciones de GitHub
Es hora de la parte principal. Desarrollaremos un flujo de trabajo de aprendizaje automático para entrenar y evaluar nuestro modelo. Este flujo de trabajo se activará cada vez que enviemos nuestro código a la rama principal o cuando alguien envíe una solicitud de extracción a la rama principal.
Para crear nuestro primer flujo de trabajo, navegue hasta la pestaña "Acciones" en la repositorio y haga clic en el texto azul "configure un flujo de trabajo usted mismo". Creará un archivo YML en el directorio .github/workflows y nos proporcionará el editor de código interactivo para agregar el código.
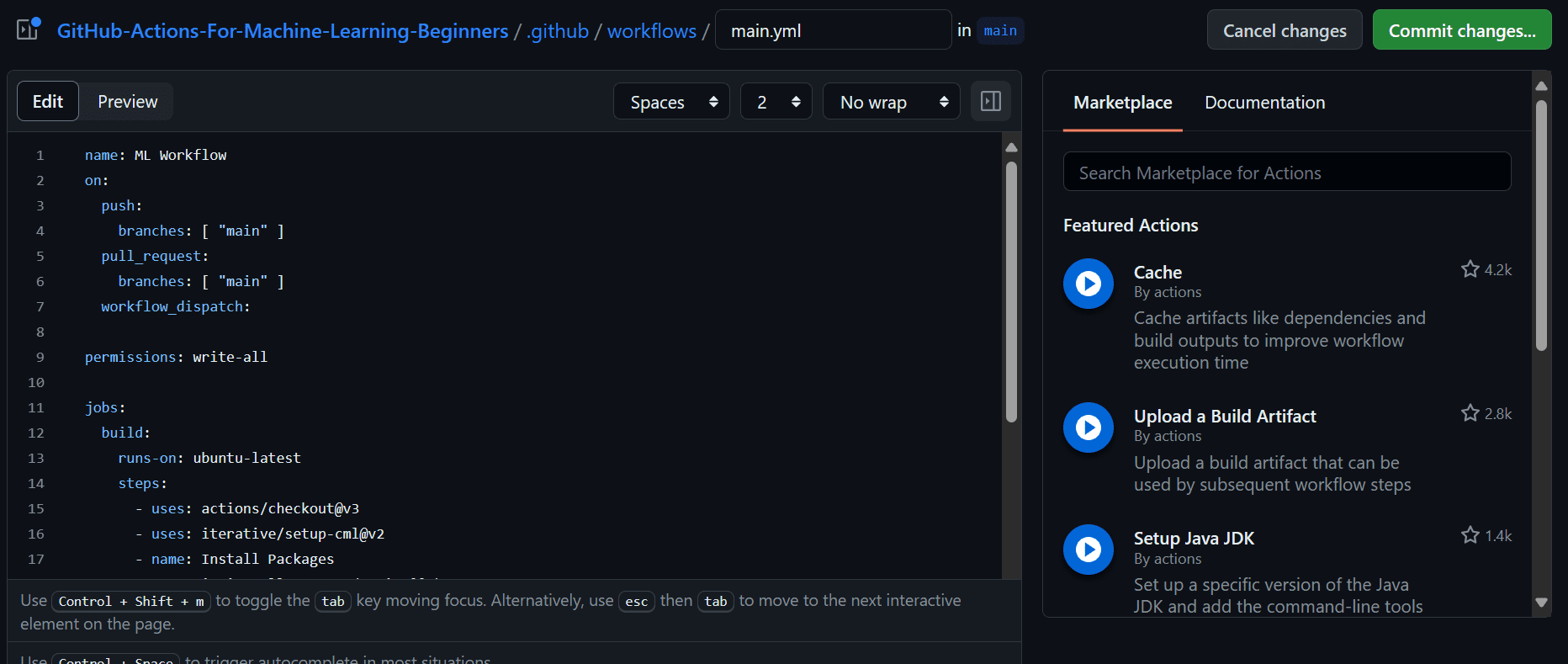
- Nombrando nuestro flujo de trabajo.
- Configurando los activadores en las solicitudes push y pull usando la clave "on".
- Proporcionando permisos de escritura a las acciones para que la acción CML pueda crear el mensaje bajo la confirmación.
- Utilizando el ejecutor de Ubuntu Linux.
- Usando la acción `actions/checkout@v3` para acceder a todos los archivos del repositorio, incluido el conjunto de datos.
- Usando la acción `iterative/setup-cml@v2` para instalar el paquete CML.
- Creando la ejecución para instalar todos los
- Crear la ejecución para formatear los archivos de Python.
- Crear la ejecución para entrenar y evaluar el modelo.
- Crear la ejecución con GITHUB_TOKEN para trasladar las métricas del modelo y el gráfico de la matriz de confusión al archivo report.md. Luego, utilizar el comando CML para generar el informe bajo el comentario de confirmación.
name: ML Workflow
on:
push:
branches: ( "main" )
pull_request:
branches: ( "main" )
workflow_dispatch:
permissions: write-all
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
with:
lfs: true
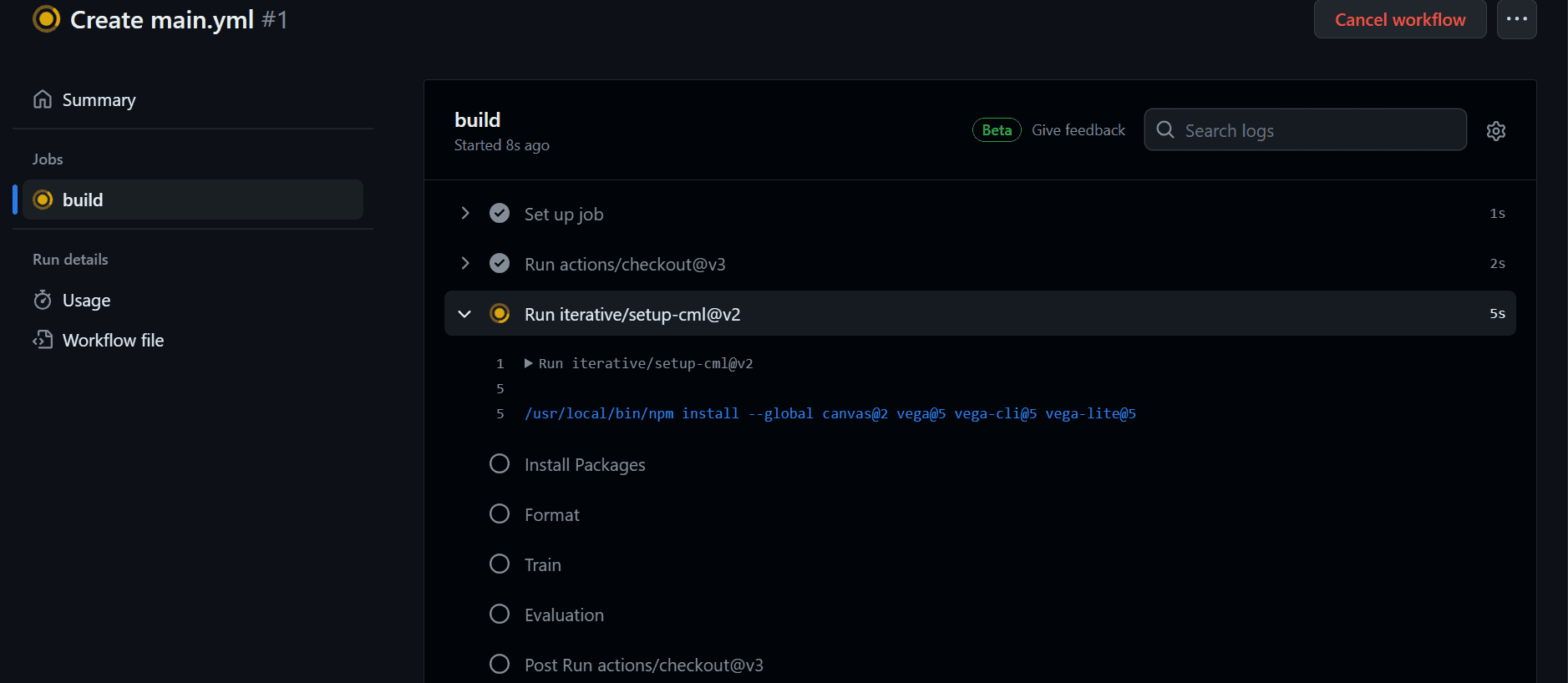
- uses: iterative/setup-cml@v2
- name: Install Packages
run: pip install --upgrade pip && pip install -r requirements.txt
- name: Format
run: black *.py
- name: Train
run: python train.py
- name: Evaluation
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
echo "## Model Metrics" > report.md
cat metrics.txt >> report.md
echo '## Confusion Matrix Plot' >> report.md
echo '!(Confusion Matrix)(model_results.png)' >> report.md
cml comment create report.md
Así es como se espera que se desarrolle en su flujo de trabajo de GitHub.
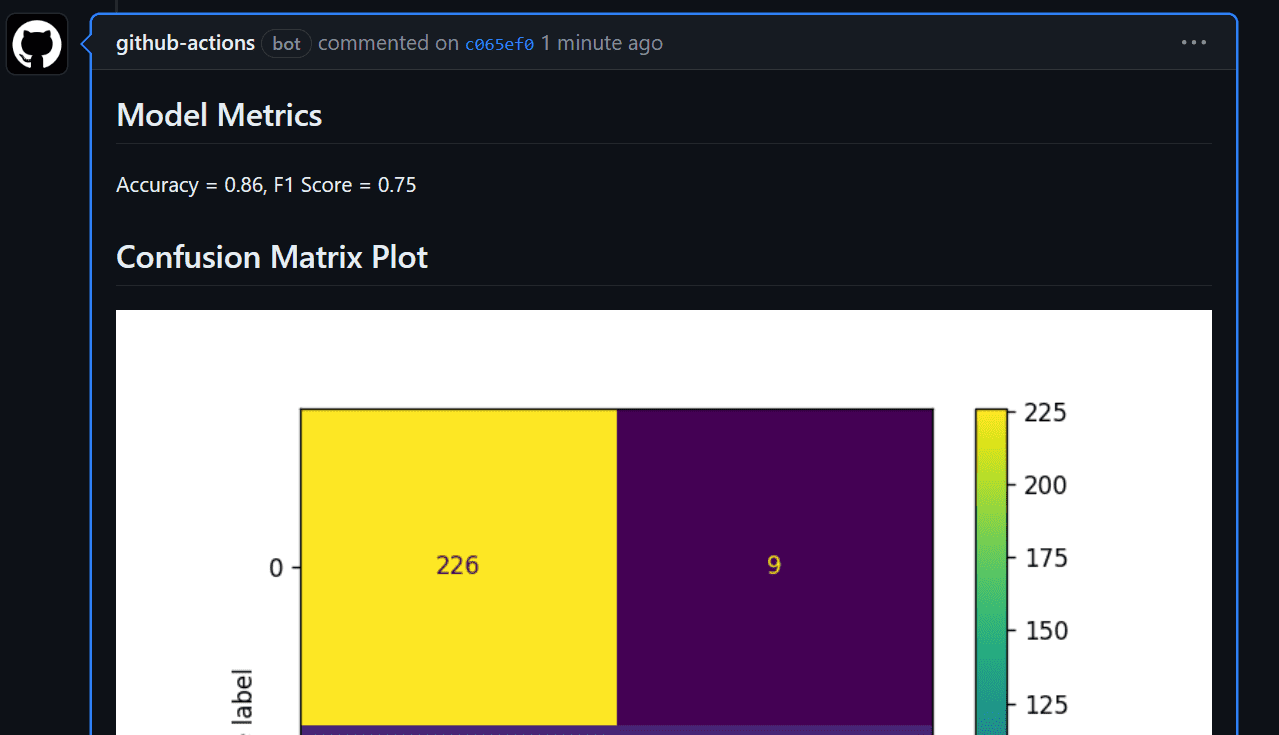
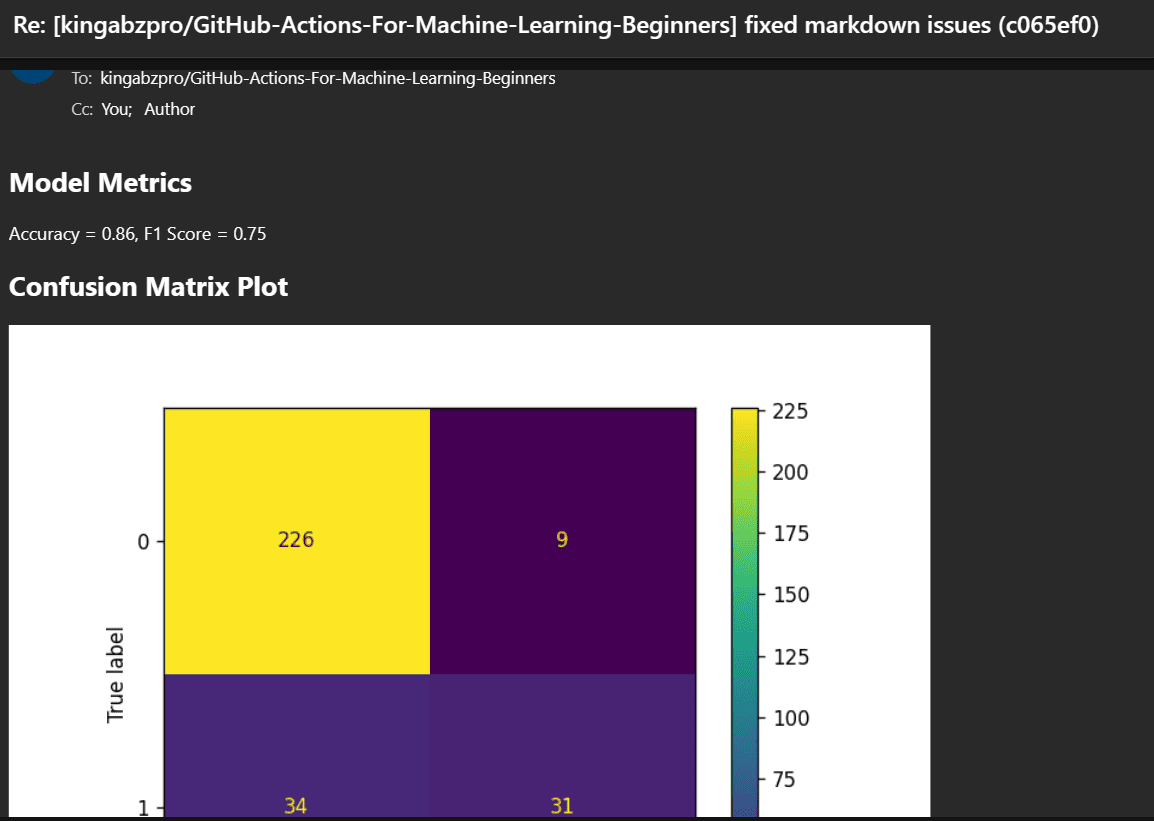
El campo de las operaciones de aprendizaje automático (MLOps) es amplio y requiere conocimientos de diversas herramientas y plataformas para construir e implementar modelos con éxito en producción. Para adentrarte en el mundo de MLOps, se recomienda seguir un tutorial completo "Una guía para principiantes sobre CI/CD para aprendizaje automático". Este tutorial te proporcionará una base sólida para implementar eficazmente técnicas MLOps.
En esta guía, se ha abordado el uso de las GitHub Actions y cómo aplicarlas para automatizar tu flujo de trabajo de aprendizaje automático. También se ha explorado el uso de acciones CML y cómo escribir scripts en formato YML para ejecutar los trabajos de forma correcta. Si aún te sientes indeciso sobre por dónde comenzar, se recomienda visitar "El único curso gratuito que necesitas para convertirte en ingeniero de MLOps".
Abid Ali Awan (@1abidaliawan) es un científico de datos profesional certificado que disfruta creando modelos de aprendizaje automático. En la actualidad, se dedica a la creación de contenidos y redacción de blogs técnicos sobre tecnologías de ciencia de datos y aprendizaje automático. Abid posee una maestría en gestión de tecnología y una licenciatura en ingeniería de telecomunicaciones. Su visión es desarrollar un producto de inteligencia artificial utilizando una red neuronal gráfica para ayudar a estudiantes que lidian con enfermedades mentales.