
Hoy, Confluent presentó la disponibilidad de su servicio serverless de Apache Flink. Flink es una tecnología ampliamente utilizada para el procesamiento de flujos, clasificada entre los cinco principales proyectos de Apache y respaldada por una diversa comunidad de contribuyentes que incluye a Alibaba y Apple. Es el pilar del procesamiento de flujos en grandes empresas como Uber, Netflix y LinkedIn.
Los usuarios de Rockset que utilizan Flink a menudo expresan las dificultades de autogestionar Flink para transformaciones de streaming. Por eso estamos emocionados de que Confluent Cloud esté simplificando el uso de Flink, proporcionando un procesamiento de flujos efectivo y eficiente al tiempo que libera a los ingenieros de la compleja gestión de la infraestructura.
Si bien es comúnmente conocido que Flink es excepcional en la filtración, unión y enriquecimiento de datos de streaming de Apache Kafka® o Confluent Cloud, lo que se reconoce menos es su creciente integración en la estructura de extremo a extremo para aplicaciones impulsadas por IA. Esto se debe a que la implementación exitosa de una aplicación de IA requiere de pipelines de generación de recuperación aumentada o "RAG", que manejan flujos de datos en tiempo real, segmentan datos, crean incrustaciones, almacenan incrustaciones y ejecutan búsquedas vectoriales.
En este artículo, exploraremos cómo RAG encaja en el mundo del procesamiento de datos en tiempo real y demostraremos un ejemplo de una aplicación de recomendación de productos que utiliza Kafka y Flink en Confluent Cloud junto con Rockset.
Comprendiendo RAG
Los grandes modelos de lenguaje (LLMs) como ChatGPT se entrenan con vastas cantidades de datos de texto disponibles hasta una cierta fecha límite. Por ejemplo, la fecha límite para GPT-4 fue abril de 2023, por lo que no estaría informado sobre eventos o desarrollos ocurridos después de ese momento. Además, si bien los LLMs se entrenan con un corpus de texto sustancial, carecen de detalles específicos del dominio, relevancia para casos de uso o conocimiento interno de la empresa. Este conocimiento específico es lo que mejora la relevancia de muchas aplicaciones, lo que resulta en respuestas más precisas.
Los LLMs también son propensos a generar respuestas inexactas o "alucinaciones". Al conectar las respuestas con información de recuperación, los LLMs pueden confiar en datos confiables para sus respuestas en lugar de depender únicamente de su base de conocimientos existente.
Establecer una base de conocimientos en tiempo real, contextual y confiable para aplicaciones de IA gira en torno a los pipelines de RAG. Estos pipelines toman datos contextuales y los introducen en un LLM para mejorar la relevancia de una respuesta. Veamos cada paso en un pipeline de RAG en el contexto del desarrollo de un motor de recomendación de productos:
- Flujo de datos: Un catálogo de productos en línea como Amazon contiene datos sobre varios productos como nombre, fabricante, descripción, precio, críticas de usuarios, etc. El catálogo se amplía a medida que se agregan nuevos productos o se realizan actualizaciones, como nuevos precios, disponibilidad, recomendaciones y más.
- Segmentación de datos: La segmentación implica dividir archivos de texto grandes en secciones más manejables para garantizar que la información más relevante se transmita al LLM. Por ejemplo, para un catálogo de productos, una sección podría consistir en el nombre del producto, la descripción y una recomendación única concatenada juntas.
- Generación de incrustaciones vectoriales: El proceso de crear incrustaciones vectoriales transforma secciones de texto en vectores numéricos que capturan las semánticas subyacentes y las relaciones contextuales del texto en un espacio multidimensional.
- Indexación de vectores: Los algoritmos de indexación ayudan en la búsqueda rápida y eficiente a través de miles de millones de vectores. Con las actualizaciones constantes del catálogo de productos, la generación de nuevas incrustaciones y su indexación ocurre en tiempo real.
- Búsqueda vectorial: Identificación de los vectores más relevantes basados en una consulta de búsqueda con tiempos de respuesta en milisegundos. Por ejemplo, un usuario navegando por "Guerras del Espacio" en un catálogo de productos buscando recomendaciones de videojuegos similares.
Si bien un pipeline de RAG describe los pasos específicos para construir aplicaciones de IA, estos pasos se asemejan a un pipeline de procesamiento de flujos tradicional donde los datos se transmiten desde múltiples fuentes, se enriquecen y se sirven a aplicaciones secundarias. Las aplicaciones impulsadas por IA comparten requisitos similares a cualquier aplicación de cara al usuario, requiriendo servicios backend confiables, eficientes y escalables.
Desafíos en el Desarrollo de Pipelines de RAG
Las arquitecturas de primeros enfoques en streaming forman la base esencial para la era de la IA. Una aplicación de recomendaciones de productos es más relevante cuando puede integrar señales sobre la disponibilidad de productos o detalles de envío en un corto periodo de tiempo. Al desarrollar aplicaciones para un rendimiento en tiempo real y a escala consistentes, una arquitectura de primeros enfoques en streaming es crucial.
Surgen varios desafíos al construir pipelines de RAG en tiempo real:
- Entrega en tiempo real de incrustaciones y actualizaciones
- Filtrado de metadatos en tiempo real
- Manejo de escala y eficiencia para datos en tiempo real
En las secciones siguientes, abordaremos ampliamente estos desafíos y profundizaremos en su aplicación específica con respecto a la búsqueda vectorial y las bases de datos vectoriales.
Entrega en Tiempo Real de Incrustaciones y Actualizaciones
Al trabajar con datos recientes, es necesario diseñar el pipeline RAG para datos en streaming. También es fundamental que se diseñen para actualizaciones en tiempo real. En un catálogo de productos, los artículos más nuevos deben tener incrustadas las representaciones generadas y añadidas al índice.
Los algoritmos de indexación para vectores no admiten nativamente las actualizaciones de manera óptima. Esto se debe a que los algoritmos de indexación están cuidadosamente organizados para búsquedas rápidas, y los intentos de actualizarlos incrementalmente con nuevos vectores deterioran rápidamente las propiedades de búsqueda rápida. Existen varios enfoques potenciales que una base de datos de vectores puede utilizar para ayudar con las actualizaciones incrementales: actualización ingenua de vectores, reindexación periódica, etc. Cada estrategia tiene consecuencias en cuanto a la rapidez con la que los nuevos vectores pueden aparecer en los resultados de búsqueda.
Filtrado de Metadatos en Tiempo Real
Los datos en streaming sobre productos en un catálogo se utilizan para generar incrustaciones vectoriales y proporcionar información contextual adicional. Por ejemplo, un motor de recomendación de productos puede querer mostrar productos similares al último producto que un usuario buscó (búsqueda vectorial) que tengan una alta calificación (búsqueda estructurada) y estén disponibles para envío con Prime (búsqueda estructurada). Estas entradas adicionales se conocen como filtrado de metadatos.
Los algoritmos de indexación están diseñados para ser grandes, estáticos y monolíticos, lo que dificulta ejecutar consultas que unan vectores y metadatos de manera eficiente. El enfoque óptimo es el filtrado de metadatos en una sola etapa que combina el filtrado con las búsquedas de vectores. Para hacer esto de manera efectiva, tanto los metadatos como los vectores deben estar en la misma base de datos, aprovechando las optimizaciones de consultas para lograr tiempos de respuesta rápidos. Casi todas las aplicaciones de IA desearán incluir metadatos, especialmente metadatos en tiempo real. ¿De qué serviría un motor de recomendación deQué sucede si el artículo recomendado está agotado?
Optimizando la eficiencia de datos en tiempo real
Implementar aplicaciones de IA puede resultar costoso rápidamente. La generación de incrustaciones vectoriales y la indexación de vectores son procesos que requieren una gran cantidad de cálculos. La capacidad de la infraestructura subyacente para manejar datos en streaming, ofreciendo un rendimiento predecible y la posibilidad de escalar según la demanda, resulta fundamental para que los ingenieros sigan aprovechando la IA.
En muchos sistemas de bases de datos de vectores, la indexación y la búsqueda se llevan a cabo en los mismos clústeres de cómputo, lo que permite un acceso más rápido a los datos. Sin embargo, esta arquitectura altamente integrada, común en sistemas como Elasticsearch, puede ocasionar conflictos de cómputo y la asignación de recursos para una capacidad máxima. En ideal, la búsqueda y la indexación de vectores deben ser procesos aislados que accedan al mismo conjunto de datos en tiempo real.
Beneficios de utilizar Confluent Cloud para Apache Flink y Rockset para RAG
Confluent Cloud para Apache Flink y Rockset, una base de datos de búsqueda y análisis diseñada para la nube, se han diseñado para admitir datos de alta velocidad, procesamiento en tiempo real y desagregación para lograr escalabilidad y resiliencia ante fallos.
Estos son algunos de los beneficios de utilizar Confluent Cloud para Apache Flink y Rockset para pipelines RAG:
- Compatible con procesamiento de flujos de alta velocidad y actualizaciones incrementales: Incorpora información en tiempo real para mejorar la relevancia de las aplicaciones de IA. Rockset es una base de datos mutable, lo que le permite actualizar eficientemente metadatos e índices en tiempo real.
- Enriquece tu pipeline RAG con filtros y uniones: Utiliza Flink para enriquecer el pipeline, generar incrustaciones de productos en tiempo real, fragmentar datos y garantizar la seguridad y privacidad de los datos. Rockset considera el filtrado de metadatos como un componente esencial, lo que permite realizar consultas SQL en vectores, texto, JSON, datos geoespaciales y de series temporales.
- Construido para escalar y velocidad de desarrollo: Escala según la demanda con servicios nativos en la nube diseñados para ofrecer eficiencia y elasticidad. Rockset separa el cómputo de indexación del cómputo de consulta para lograr un rendimiento predecible a escala.
Arquitectura para Recomendaciones potenciadas por IA
Exploraremos cómo podemos aprovechar Kafka y Flink en Confluent Cloud con Rockset para desarrollar un pipeline RAG en tiempo real destinado a un motor de recomendaciones potenciado por IA.
En este ejemplo de recomendaciones potenciadas por IA, utilizaremos un conjunto de datos de reseñas de productos de Amazon públicamente disponibles, que incluye reseñas de productos y metadatos asociados como nombres de productos, características, precios, categorías y descripciones.
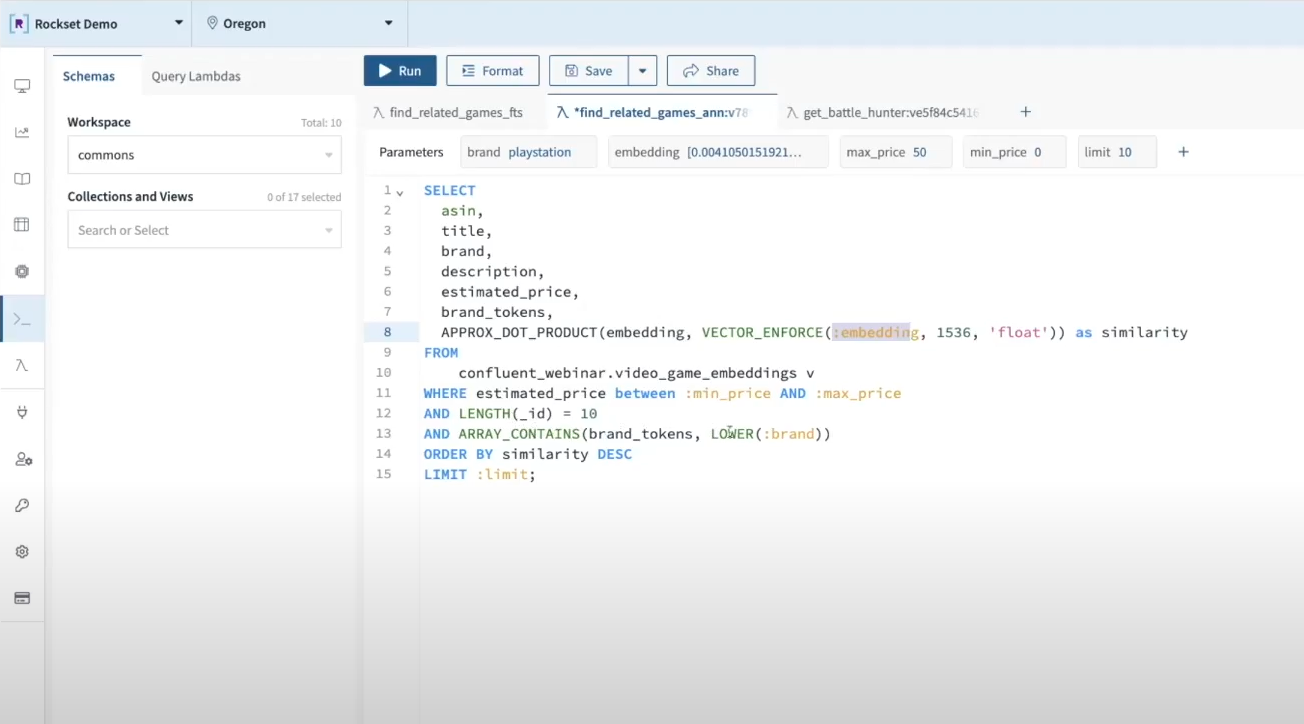
Nos enfocaremos en encontrar videojuegos similares a Starfield compatibles con la consola Playstation. Dado que Starfield es un videojuego popular en Xbox, los jugadores que utilizan Playstation pueden estar interesados en encontrar juegos similares compatibles con su sistema. Utilizaremos Kafka para transmitir las reseñas de productos, Flink para generar incrustaciones de productos y Rockset para indexar las incrustaciones y metadatos para la búsqueda vectorial.
Sobre Confluent Cloud
Confluent Cloud es una plataforma de streaming de datos completamente gestionada que permite transmitir vectores y metadatos desde cualquier ubicación donde se encuentren los datos fuente, ofreciendo conectores nativos fáciles de usar. Este servicio gestionado, desarrollado por los creadores de Apache Kafka, garantiza escalabilidad elástica, resiliencia con un SLA de tiempo de actividad del 99.99% y baja latencia predecible. Configuramos un productor de Kafka para publicar eventos en un clúster de Kafka. Este productor recopila datos en tiempo real del catálogo de productos de Amazon.com y los envía a Confluent Cloud. Todo se ejecuta en Java utilizando Docker Compose para configurar el productor de Kafka y Apache Flink. En Confluent Cloud, creamos un clúster para recomendaciones de productos con inteligencia artificial, con el tema de metadatos de productos. Para filtrar, enriquecer y procesar fácilmente el flujo de datos de Confluent con Flink, el estándar de facto en el procesamiento de flujos que ahora está disponible como una solución sin servidor y completamente gestionada en Confluent Cloud. Experimente Kafka y Flink juntos como una plataforma unificada, con monitoreo, seguridad y gobernanza totalmente integrados. Para procesar los metadatos de productos y generar incrustaciones vectoriales al vuelo, utilizamos Flink en Confluent Cloud. Durante el procesamiento de flujos, cada reseña de producto se consume de forma individual, se extrae el texto de la reseña y se envía a OpenAI para generar incrustaciones vectoriales. Estas incrustaciones se adjuntan como eventos a un nuevo tema de incrustaciones de productos, ya que no contamos con un algoritmo interno para este ejemplo y necesitamos crear una función definida por el usuario para invocar a OpenAI y generar las incrustaciones utilizando Flink autoadministrado.
We can explore the Confluent console to analyze the products.embeddings topic created using Flink and OpenAI.
Rockset
Rockset provides a cloud-native search and analytics database that seamlessly integrates with Kafka for Confluent Cloud. By leveraging Rockset’s architecture, indexing, and vector search operations can be executed independently to ensure optimal and consistent performance. Rockset is powered by RocksDB and supports efficient incremental updates to vector indexes. It utilizes indexing techniques based on the renowned FAISS library, which is well-known for its exceptional update support.
Plataforma Rockset: Una solución integral para la búsqueda y aplicación de datos en tiempo real
Rockset funciona como un intermediario con Confluent Cloud, recolectando información en tiempo real del tema product.embeddings e indexándola para la búsqueda de vectores.
Al ejecutar una consulta de búsqueda como "encuéntrame todos los vectores similares a 'space wars' que sean compatibles con PlayStation y cuesten menos de $50″, la aplicación envía una solicitud a OpenAI para convertir 'space wars' en un vector y luego encuentra los productos más similares en el catálogo de Amazon utilizando Rockset como base de datos de vectores. Rockset utiliza SQL como su lenguaje de consulta, lo que facilita el filtrado de metadatos con una cláusula WHERE de SQL.
Stack Nativo en la Nube para Aplicaciones Impulsadas por IA en Datos en Tiempo Real
La oferta sin servidor de Flink de Confluent completa el stack nativo en la nube de extremo a extremo para aplicaciones impulsadas por IA. Los equipos de ingeniería pueden ahora concentrarse en la construcción de aplicaciones de IA de última generación en lugar de gestionar la infraestructura. Los servicios en la nube subyacentes escalarán según la demanda, asegurando un rendimiento predecible sin el costoso sobreaprovisionamiento de recursos.
Como se ha visto en este blog, los pipelines de RAG se benefician de las arquitecturas de streaming en tiempo real, observando mejoras en la relevancia y confiabilidad de las aplicaciones de IA. Al diseñar para pipelines de RAG en tiempo real, el stack subyacente debe ser capaz de manejar datos de streaming, actualizaciones y filtrado de metadatos como funciones principales.
Construir aplicaciones de IA en datos en tiempo real nunca ha sido tan sencillo. Exploramos los fundamentos de construir un motor de recomendación de productos impulsado por IA.