


Las empresas a menudo necesitan agregar temas porque es esencial para organizar, simplificar y optimizar el procesamiento de la transmisión de datos. Permite un análisis eficiente, facilita el desarrollo modular y mejora la eficacia general de las aplicaciones de streaming. Por ejemplo, si hay grupos separados y hay temas con el mismo propósito en los diferentes grupos, entonces es útil agregar el contenido en un solo tema.
Esta publicación de blog le explica cómo puede utilizar la replicación sin prefijo con Streams Replication Manager (SRM) para agregar temas de Kafka de múltiples fuentes. Para ser específicos, profundizaremos en un escenario de replicación sin prefijo que implica la agregación de dos temas de dos grupos de Kafka separados en un tercer grupo.
Este tutorial demuestra cómo configurar el servicio SRM para replicación sin prefijo, cómo crear y replicar temas con herramientas de línea de comandos (CLI) Kafka y SRM, y cómo verificar su configuración usando Streams Messaging Manger (SMM). No se analizan la configuración de seguridad y otras configuraciones avanzadas.
Antes de que empieces
El siguiente tutorial supone que está familiarizado con conceptos de SRM como replicaciones y flujos de replicación, políticas de replicación, la arquitectura de servicio básica de SRM, así como la replicación sin prefijo. Si no, puedes consultar esta publicación de blog relacionada. Alternativamente, puede leer sobre estos conceptos en nuestro Descripción general de SRM.
Resumen del escenario
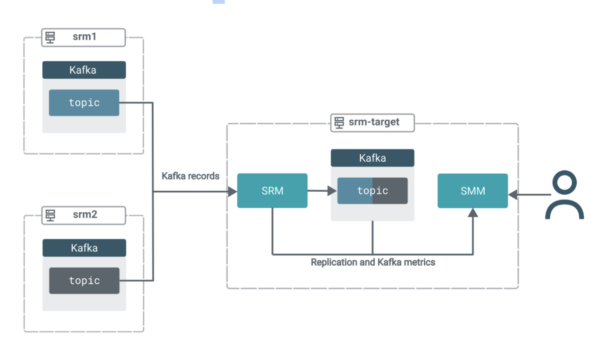
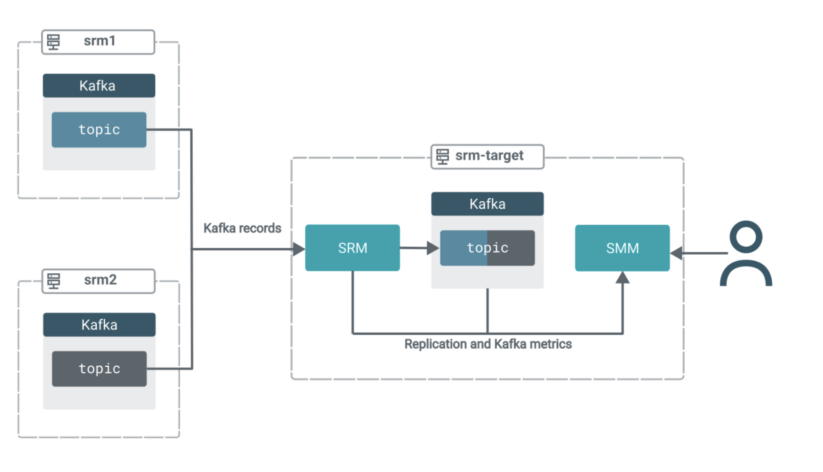
En este escenario tienes tres grupos. Todos los grupos contienen Kafka. Además, el clúster de destino (objetivo srm) tiene SRM y SMM implementados.
El servicio SRM en objetivo srm se utiliza para extraer datos de Kafka de los otros dos grupos. Es decir, esta configuración de replicación funcionará en modo pull, que es la arquitectura recomendada por Cloudera para implementaciones de SRM.
En el modo de extracción, el servicio SRM (específicamente las instancias de la función del controlador SRM) replica datos extrayéndolos de sus fuentes. Entonces, en lugar de tener SRM en los clústeres de origen que envían los datos a los clústeres de destino, se utiliza SRM ubicado en el clúster de destino para extraer los datos a su clúster Kafka ubicado en el mismo lugar.Se recomienda el modo de extracción, ya que es el tipo de implementación que proporciona la mayor cantidad de resiliencia frente a diversos problemas de tiempo de espera e inestabilidad de la red. Puede encontrar una explicación más detallada del modo pull en los documentos oficiales.
Los registros de ambos temas de origen se agregarán en un solo tema en el grupo de destino. Mientras tanto, podrá utilizar las potentes funciones de interfaz de usuario de SMM para monitorear y verificar lo que está sucediendo.
Configurar SRM
Primero, debe configurar el servicio SRM ubicado en el clúster de destino.
SRM necesita saber qué clústeres de Kafka (o servicios de Kafka) son objetivos y cuáles son fuentes, dónde están ubicados, cómo puede conectarse y comunicarse con ellos y cómo debe replicar los datos. Esto se configura en Cloudera Manager y es un proceso de dos partes. Primero, define las credenciales de Kafka y luego configura el servicio SRM.
Definir las credenciales de Kafka
Usted define sus clústeres de origen (externos) utilizando las credenciales de Kafka. Una credencial Kafka es un elemento que contiene las propiedades requeridas por SRM para establecer una conexión con un clúster. Puede pensar en una credencial Kafka como la definición de un único clúster. Contiene el nombre (alias), la dirección (servidores de arranque) y las credenciales que SRM puede usar para acceder a un clúster específico.
- En el administrador de Cloudera, vaya a la página Administración > Cuentas externas > Credenciales de Kafka.
- Haga clic en "Agregar credenciales de Kafka".
- Configure la credencial.
La configuración en este tutorial es mínima y no segura, por lo que solo necesita configurar las líneas de Nombre, Servidores Bootstrap y Protocolo de seguridad. El protocolo de seguridad en este caso es PLAINTEXT.
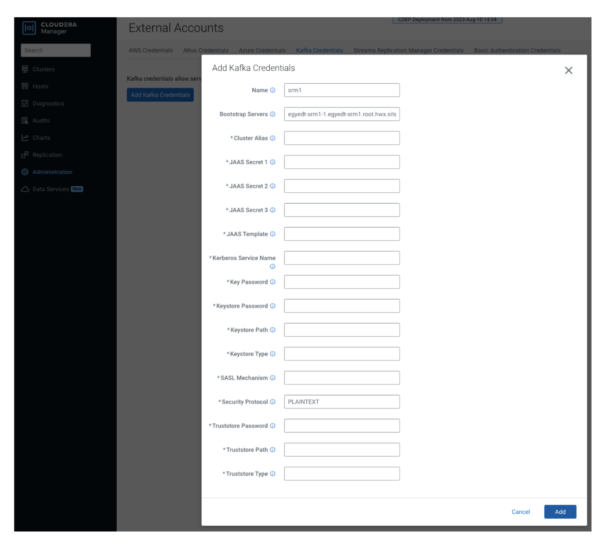
4. Haga clic en "Agregar" una vez que haya terminado y repita el paso anterior para el otro clúster (srm2).
Configurar el servicio SRM
Una vez configuradas las credenciales, deberá configurar varias propiedades del servicio SRM. Estas propiedades especifican el clúster de destino (ubicado conjuntamente), le indican a SRM qué replicaciones deben habilitarse y que la replicación debe realizarse en modo sin prefijo. Todo esto se hace en la página de configuración del servicio SRM.
1. Desde la página de inicio de Cloudera Manager, seleccione el servicio "Streams Replication Manager".
2. Vaya a "Configuración".
3. Especifique el alias del clúster coubicado con “Streams Replication Manager Alias del clúster Kafka coubicado.”
El alias del clúster ubicado conjuntamente es el alias (nombre corto) del clúster de Kafka con el que se implementa SRM junto con. Todos los clústeres de una implementación de SRM tienen alias. Los alias se utilizan para hacer referencia a los clústeres al configurar propiedades y al ejecutar el control-srm herramienta. Establezca esto en:
Tenga en cuenta que solo necesita especificar el alias del clúster Kafka ubicado en el mismo lugar; no se finaliza el ingreso de información de conexión como lo hizo para los clústeres externos. Esto se debe a que Cloudera Manager pasa esta información automáticamente a SRM.
4. Especificar Cuentas Kafka externas.
Esta propiedad debe contener los nombres de las credenciales de Kafka que creó en un paso anterior. Esto le indica a SRM qué credenciales de Kafka debe importar a su configuración. Establezca esto en:

5. Especifique todos los alias de clúster con el alias "Clúster de Streams Replication Manager".
La propiedad contiene una lista delimitada por comas de todos los alias del clúster. Es decir, todos los alias que agregó anteriormente a las propiedades de alias de clúster Kafka ubicados conjuntamente en Streams Replication Manager y cuentas Kafka externas. Establezca esto en:

6. Especifique el destino de la función del controlador con el clúster de destino del controlador de Streams Replication Manager.
La propiedad contiene una lista delimitada por comas de todos los alias del clúster. Es decir, todos los alias que agregó anteriormente a las propiedades de alias de clúster Kafka ubicados conjuntamente en Streams Replication Manager y cuentas Kafka externas. Establezca esto en:

7. Especifique los objetivos de la función de servicio con el clúster de destino del servicio de Streams Replication Manager.
Esta propiedad especifica el clúster desde el que la función del servicio SRM recopilará métricas de replicación (es decir, monitor). En el modo de extracción, las funciones de servicio siempre deben apuntar a su clúster ubicado en el mismo lugar. Establezca esto en:
8. Especifique replicaciones con las configuraciones de replicación de Streams Replication Manager.
Esta propiedad es versátil y se utiliza para configurar muchas propiedades de SRM que no están disponibles directamente en Cloudera Manager. Pero lo más importante es que se utiliza para especificar sus replicaciones. Elimine el valor predeterminado y agregue lo siguiente:

9. Seleccione "Habilitar replicación sin prefijo"
Esta propiedad permite la replicación sin prefijo y le indica a SRM que use el Política de replicación de identidad, Cuál es el Política de replicación que se replica sin prefijos.
10. Revise su configuración, debería verse así:
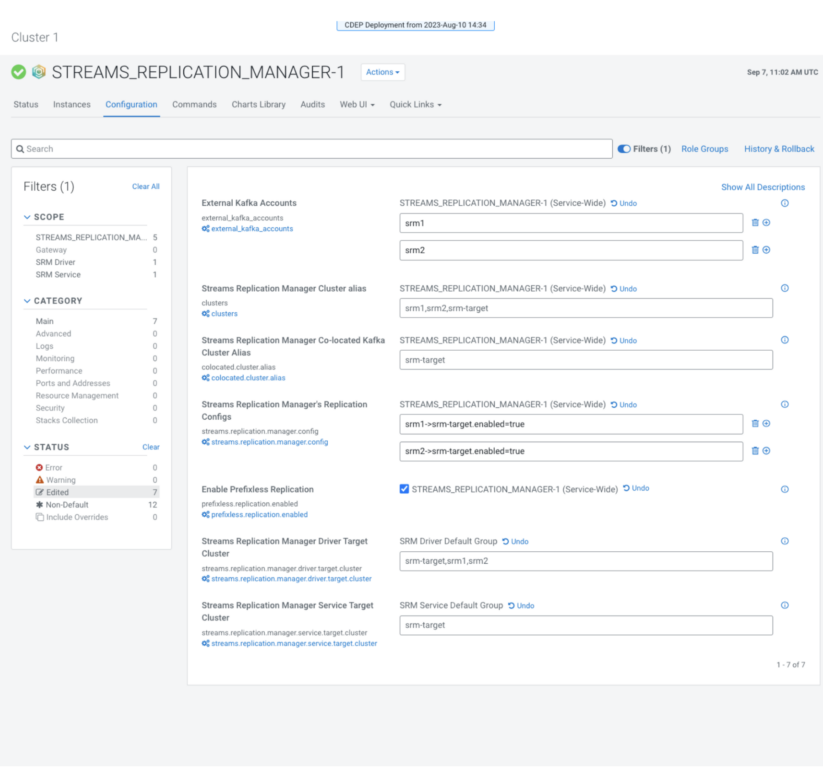
13. Haga clic en "Guardar cambios" y reinicie SRM.
Crear un tema, producir algunos registros.
Ahora que la configuración de SRM está completa, necesita crear uno de sus temas de origen y generar algunos datos. Esto se puede hacer usando el prueba-de-perf-del-productor-de-kafka Herramienta CLI.
Esta herramienta crea el tema y produce los datos de una sola vez. La herramienta está disponible de forma predeterminada en todos los clústeres de CDP y se puede llamar directamente escribiendo su nombre. No es necesario especificar rutas completas.
- Usando SSH, inicie sesión en uno de los hosts de su clúster de origen.
- Crea un tema y produce algunos datos.
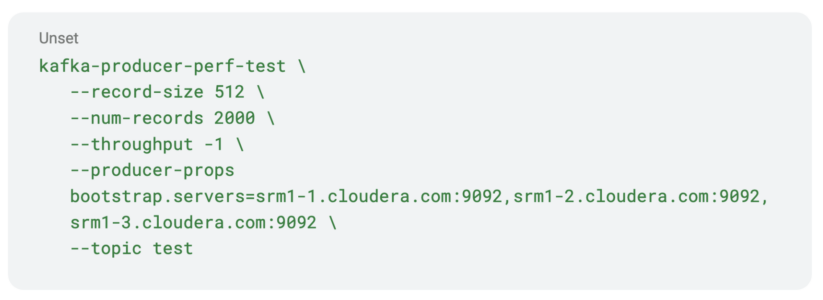
Observe que la herramienta producirá 2000 registros. Esto será importante más adelante, cuando verifiquemos la replicación en la interfaz de usuario de SMM.
replicar el tema
Entonces, tienes SRM configurado y tu tema está listo. Repitamos.
Aunque sus replicaciones están configuradas, SRM y los clústeres de origen están conectados, los datos no fluyen, la replicación está inactivo. Para activar la replicación, debe utilizar la herramienta CLI srm-control para especificar qué temas se deben replicar.
Con la herramienta, puede manipular la replicación para permitir y denegar listas (o filtros de temas), que controlan qué temas se replican. De forma predeterminada, no se replica ningún tema, pero puedes cambiar esto con unos simples comandos.
- Usando SSH, inicie sesión en el clúster de destino (objetivo srm).
- Ejecute los siguientes comandos para iniciar la replicación.

Observe que a pesar de que el tema en srm2 aún no existe, también agregamos el tema a la lista de replicación permitida. El tema se creará más tarde. En este caso, estamos activando su replicación con antelación.
Perspectivas con SMM
Ahora que la replicación está activada, la implementación se encuentra en el siguiente estado:
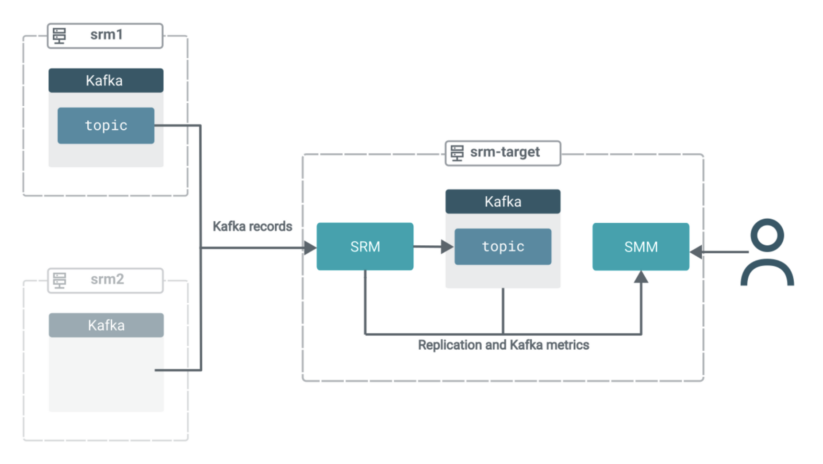
En los próximos pasos, cambiaremos el enfoque a SMM para demostrar cómo puede aprovechar su interfaz de usuario para obtener información sobre lo que realmente sucede en su clúster objetivo.

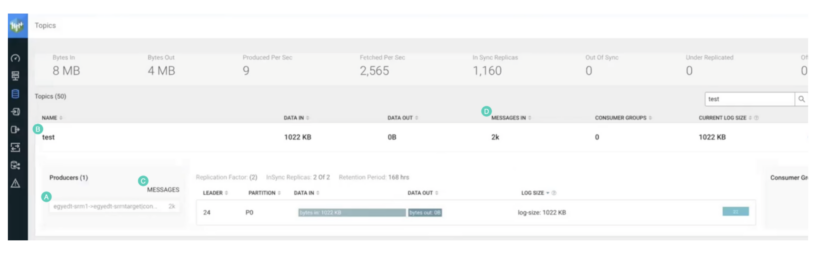
Observe lo siguiente:
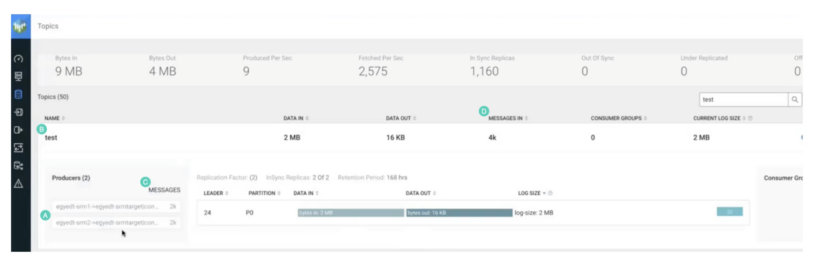
- El nombre de la replicación está incluido en el nombre del productor que creó el tema. La notación -> significa replicación. Por lo tanto, el tema fue creado con replicación.
- El nombre del tema es el mismo que en el clúster de origen. Por lo tanto, se replicó con replicación sin prefijo. No tiene el alias del clúster de origen como prefijo.
- El productor escribió 2.000 discos. Esta es la misma cantidad de registros que produjo en el tema fuente con kafka-producer-perf-test.
- “MENSAJES EN” muestra 2000 registros. De nuevo, la misma cantidad que se produjo originalmente.
A la agregación
Después de replicar con éxito los datos sin prefijo, es hora de avanzar y agregar los datos del otro clúster de origen. Primero deberá configurar el tema de prueba en el segundo clúster de origen (srm2), ya que aún no existe. Este tema debe tener exactamente el mismo nombre y configuraciones que el del primer clúster de origen (srm1).
Para hacer esto, necesitas ejecutar prueba-de-perf-del-productor-de-kafka de nuevo, pero esta vez en una serie de srm2 grupo. Además, para el arranque deberá especificar srm2 Hospedadores.

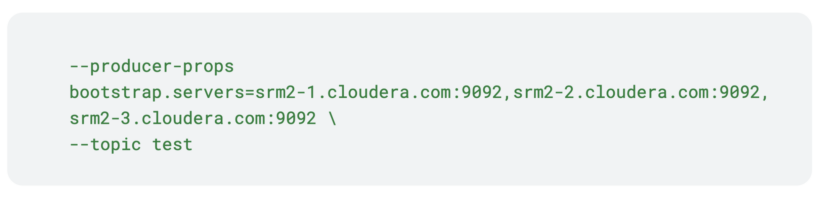
Observe cómo solo los programas de arranque son diferentes del primer comando. Esto es crucial, los temas de los dos clústeres deben ser idénticos en nombre y configuración. De lo contrario, el tema en el clúster de destino cambiará constantemente entre dos estados de configuración. Además, si los nombres no coinciden, no se producirá la agregación.
Una vez que el productor termina de crear el tema y producir los 2000 registros, el tema se replica inmediatamente. Esto se debe a que activamos previamente la replicación del tema de prueba en un paso anterior. Además, los registros de temas se agregan automáticamente al tema de prueba en objetivo srm.
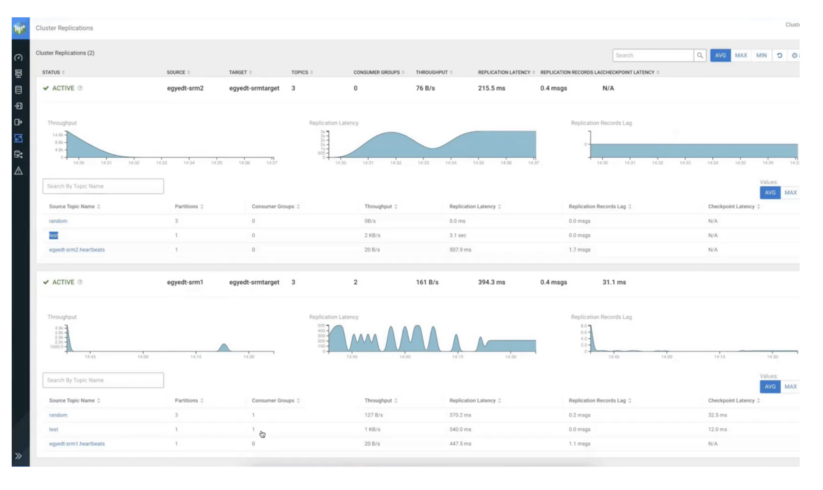
Puede verificar que se haya producido la agregación echando un vistazo al tema en la interfaz de usuario de SMM.
Lo siguiente indica que se ha producido agregación:
- Ahora hay dos productores en lugar de uno. Ambos contienen el nombre de la replicación. Por lo tanto, el tema obtiene registros de dos fuentes de replicación.
- El nombre del tema sigue siendo el mismo. Por lo tanto, la replicación sin perfix sigue funcionando.
- Ambos productores escribieron 2.000 discos cada uno.
- “MENSAJES EN” muestra 4.000 registros.

 Resumen
Resumen
En esta publicación de blog, analizamos cómo se puede utilizar la función de replicación sin prefijo de SRM para agregar temas de Kafka de múltiples clústeres en un único clúster de destino.
Aunque la agregación estaba en el centro de atención, tenga en cuenta que la replicación sin prefijo también se puede utilizar para escenarios de replicación sin tipo de agregación. Por ejemplo, es la herramienta perfecta para migrar esa antigua implementación de Kafka que se ejecuta en CDH, HDP o HDF a CDP.
Si desea obtener más información sobre SRM y Kafka en CDP Private Cloud Base, vaya al portal de documentación de Cloudera y consulte Conceptos de mensajería de transmisiones, Instrucciones de transmisión de mensajesy/o el Guía de migración de mensajería de Streams.
Para ponerse manos a la obra con SRM, descargue la edición Cloudera Stream Processing Community aquí.
¿Interesado en unirse a Cloudera?
En Cloudera, estamos trabajando en el ajuste de paquetes de software relacionados con big data (basados en proyectos de código abierto de Apache) para brindarles a nuestros clientes una experiencia perfecta mientras ejecutan sus proyectos de análisis o aprendizaje automático en conjuntos de datos de escala de petabytes. Consulta nuestro sitio web para una prueba de manejo!
Si está interesado en big data, le gustaría saber más sobre Cloudera o simplemente está dispuesto a conversar con expertos en tecnología, visite nuestra elegante oficina de Budapest en nuestra próxima reuniones.
O simplemente visite nuestro pagina de carreras¡Y conviértete en un Clouderano!